کسب درآمد از هوش مصنوعی | معرفی ۱۰ روش برتر

۲۶
تیر
استفاده از هوش مصنوعی (AI)، به سرعت روش کار و زندگی ما را تغییر می دهد. هوش مصنوعی در بسیاری از مشاغل، از چت بات ها و دستیاران مجازی گرفته تا تجزیه و تحلیل داده ها و یادگیری ماشینی، به ابزاری حیاتی تبدیل شده است. اما آیا متوجه شده اید که کسب درآمد از هوش مصنوعی می تواند بسیار پرسود باشد؟
روشهای ساده زیادی برای کسب درآمد از هوش مصنوعی وجود دارد. در این مطلب، ما ۱۰ روش برتر را که به شما در کسب درآمد با استفاده از ابزارهای هوش مصنوعی کمک می کند، مورد بحث قرار داده ایم. برای آشنایی بیشتر با این ابزارها تا انتهای مطلب با ما همراه باشید.
نحوه کسب درآمد از هوش مصنوعی
ابزارهای هوش مصنوعی مانند ChatGPT و DALL-E به گونهای طراحی شدهاند که بصری باشند و برای همه، از جمله مبتدیان، قابل دسترس باشند. اکثر این ابزارها برای استفاده نیاز به یک وب سایت دارند. اما خوشبختانه، با استفاده از Hostinger Website Builder میتوانید به راحتی یک وبسایت حرفهای بسازید و به کارهای خود ادامه دهید.
یکی از روشهای کسب درآمد از هوش مصنوعی، توسعه و ارائه خدمات و محصولات مبتنی بر هوش مصنوعی است. میتوانید به عنوان یک توسعهدهنده AI برنامهها و الگوریتمهای آن را طراحی و پیادهسازی کنید و آنها را به شرکتها یا مشتریان فروخته و درآمد کسب کنید.
علاوه بر آن، میتوانید به عنوان متخصص هوش مصنوعی در پروژههای مرتبط با آن همکاری کرده و از طریق پروژههای مشتریان کسب درآمد کنید. برخی از مثالهای این پروژهها شامل تحلیل دادهها، پیشبینی الگوها و پردازش زبان طبیعی میباشد.
همچنین، میتوانید به عنوان مشاور هوش مصنوعی فعالیت کنید و به سازمانها و شرکتها در بهینهسازی فرآیندها و استراتژیهای هوشمندانه کمک کنید. در این حالت، میتوانید از طریق مشاوره و خدمات مرتبط با هوش مصنوعی درآمد کسب کنید.
راه های کسب درامد از هوش مصنوعی
هوش مصنوعی به عنوان یکی از فناوریهای جذاب و پرکاربرد، امکانات بسیاری را برای کسب درآمد فراهم میکند. با پیشرفت تکنولوژی هوش مصنوعی و یادگیری ماشینی، به صنایع مختلف ازجمله فناوری اطلاعات و کامپیوتر، بهبود عملکرد فرآیندها و سیستمها کمک کرده است. امروزه میتوان با استفاده از روشهای متعددی درآمدی از هوش مصنوعی کسب کرد که در ادامه چند مورد از آنها را بیان می کنیم.
۱- فروش دوره های دیجیتال آموزش هوش مصنوعی
فروش دوره های دیجیتال آموزش هوش مصنوعی یکی از عالی ترین راه های کسب درامد از هوش مصنوعی، با استفاده از ابزارهای آن است. اگر می خواهید فروش دوره های هوش مصنوعی را به صورت آنلاین شروع کنید، چندین مرحله وجود دارد که باید آنها دنبال کنید.
ابتدا، یک پلتفرم دوره دیجیتالی را انتخاب کنید که استفاده از آن آسان بوده و دارای مجموعه ای قوی از ویژگی ها باشد. ClickFunnels یکی از بهترین پلتفرمهای دوره دیجیتال موجود است. این پلتفرم کاربر پسند، قابل تنظیم است و تمام ویژگی هایی را که برای ایجاد و فروش دوره های خود نیاز دارید، دارد.
هنگامی که پلتفرم دوره دیجیتال خود را انتخاب کردید، باید جایگاه و مخاطب هدف خود را شناسایی کنید. این به شما کمک می کند دوره ای متمرکز و ارزشمند ایجاد کنید که نیازهای مخاطبان شما را برآورده کند. شما باید از مهارت ها و تخصص هوش مصنوعی خود برای ایجاد محتوای دوره ای استفاده کنید که برای مخاطبان شما ارزش ایجاد کند.
برای ایجاد محتوای دوره، میتوانید از چندین ابزار هوش مصنوعی در دسترس استفاده کنید که میتواند به شما در کارهایی مانند ایجاد محتوا، صداگذاری و ویرایش ویدیو کمک کند. این ابزارها ایجاد محتوای باکیفیت را برای شما آسانتر میکنند.
هنگامی که دوره خود را ایجاد کردید، باید آن را برای مخاطبان هدف خود تبلیغ کنید. شما می توانید از پلتفرم های رسانه های اجتماعی، بازاریابی ایمیلی و سایر کانال های بازاریابی برای تبلیغ دوره خود و جذب دانشجویان بالقوه استفاده کنید.
وقتی نوبت به قیمت گذاری دوره شما می رسد، باید قیمت را بر اساس ارزشی که ارائه می دهد و قیمت دوره های مشابه در حوزه خود تعیین کنید. هنگامی که قیمت خود را تعیین کردید، می توانید دوره خود را راه اندازی کرده و شروع به فروش کنید.
فروش دوره های دیجیتال آموزش هوش مصنوعی یک راه عالی برای کسب درآمد از هوش مصنوعی و مهارت های شما است. با استفاده از قدرت ابزارها و پلتفرمهای هوش مصنوعی مانند Teachable، میتوانید دورههای با ارزشی را ایجاد و بفروشید. این کار مخاطبانتان کمک میکند یاد بگیرند و رشد کنند و در عین حال درآمد غیرفعالی برای شما ایجاد نمایند.
۲- تولید محتوا با هوش مصنوعی
هر کسب و کاری در جهان برای بقا و کسب درآمد به مشتریان نیاز دارد. برای تحقق این امر، مهمترین مهارت تولید محتوا است. محتوانویسان حرفه ای می توانند برای از شغل هزاران دلار درآمد داشته باشند، زیرا هر کسب و کاری به خدمات آنها نیاز دارد. شما می توانید از نویسندگان هوش مصنوعی برای تولید انواع محتواها، برای سایر مشاغل بدون اینکه متخصص باشید، استفاده کنید.
ابزارهای هوش مصنوعی مانند Jasper.ai به شما این امکان را میدهند که در چند دقیقه نسخههایی با فروش بالا ایجاد کنید. هنگام استفاده از نرمافزار هوش مصنوعی، نیازی نیست ساعتها برای تکمیل نسخه فروش صرف کنید.
برای کسب درآمد از هوش مصنوعی به وسیله تولید محتوا باید کسب و کارهای بیابید که دارای وب سایت هستند، تبلیغات اجرا کرده و یا محتوا برای جذب مشتریان جدید ایجاد می کنند. شما می توانید با این افراد تماس بگیرید و خدمات خود را ارائه دهید. به آنها بگویید چگونه می توانید مشکلات آنها را برطرف کنید و نسخه فروش بهتری برای تجارت آنها ایجاد نمایید.
۳- ساخت و فروش لوگو
چه شما یک کسب و کار داشته یا یک برند شخصی داشته باشید، همه به یک لوگوی چشم نواز نیاز دارند. شما می توانید با ساخت و فروش لوگو با AI، کسب درآمد کنید. برای این کار نیازی نیست که یک طراح گرافیک حرفه ای باشید. با ابزار هوش مصنوعی Logoai می توانید به راحتی و بدون هیچ تجربه ای لوگوهایی با ظاهر حرفه ای ایجاد کنید.
برای کسب درآمد برای ایجاد لوگو برای مشاغل، باید به بازارهایی مانند Fiverr یا ۴۸hourslogo بپیوندید و طراحی لوگو را پیشنهاد دهید. همچنین می توانید با شرکت ها و وبسایت های داخلی که در زمینه سفارش ساخت و فروش لوگو فعالیت می کنند، همکاری کنید.
این مقاله را حتما بخوانید: تولید محتوا عربی + سئو سایت عربی [SEO العربية + إنتاج المحتوى]
قیمت هر لوگو می تواند از ۱۰ دلار تا صدها دلار در دنیا متغیر باشد. به این ترتیب می توانید درامد دلاری با هوش مصنوعی را نیز تجربه کنید. برای کسب درآمد اضافی، میتوانید به عنوان یک گزینه افزودنی، محتوای رسانههای اجتماعی را برای کسبوکار ایجاد کنید. برای افزایش فروش خود نیز می توانید بسته های قیمتی ایجاد کنید.
۴- کسب درآمد با فریلنسری
یکی از بهترین کارهای جانبی آنلاین برای کسب درآمد از هوش مصنوعی، نوشتن آزاد یا همانفریلنسری است. این کاری است که می توانید از هر کجای دنیا انجام دهید. نوشتن مقاله به عنوان یک نویسنده آزاد راهی عالی برای کسب درآمد آنلاین است و با کمک هوش مصنوعی می توانید این روند را تسریع کنید.
با استفاده از ابزاری مانند Jasper.ai و ChatGPT شما می توانید مقالات را با سرعت بیشتری بنویسید. با Copysmith نیز می توانید محتواهایی را ایجاد کنید که شامل موارد زیر می باشد:
- محتوای وب سایت
- خبرنامه های ایمیل
- محتوای رسانه های اجتماعی
- آگهی ها
- مقالات سئو
- توضیحات محصول
۵- فروش طرح هنری تولید شده توسط هوش مصنوعی
شما می توانید بدون اینکه یک طراح گرافیک حرفه ای باشید، از فروش آثار هنری تولید شده توسط هوش مصنوعی درآمد کسب کنید. برای مثال PromptBase به شما امکان می دهد از هنرهای تولید شده توسط هوش مصنوعی درآمد کسب کنید.
این امکان در ابزارهای هوش مصنوعی DALL-E، GTP-3، Stable Diffusion و Midjourney نیز وجود دارد. اعلان مجموعه ای از دستورالعمل هایی است که برای ایجاد تصاویر به هوش مصنوعی داده می شود. شما می توانید به برنامه یک دستور بسیار ابتدایی مانند یک رنگ یا شی بدهید و بر اساس ورودی شما یک تصویر گرافیکی یا نقاشی ایجاد می کند.
با سیستمهای هوش مصنوعی مانند DALL-E، Stable Diffusion و Midjourney نیز میتوانید این درخواستها را ایجاد کرده و تصاویر را تولید کنید. آنچه PromptBase به شما اجازه می دهد این است که این دستورات را فهرست کرده و بفروشید. همچنین میتوانید درخواستهایی را در پلتفرم پیدا یا ایجاد کنید.
برای شروع کسب درآمد از هوش مصنوعی با هنر دیجیتال، می توانید حساب خود را در PromptBase ایجاد کنید و شروع به فروش محصولات خود در این پلتفرم نمایید.
۶- ساخت تبلیغات با ابزارهای هوش مصنوعی برای سایر مشاغل
بسیاری از کسب و کارها برای ایجاد تبلیغات دیجیتال با مشکل مواجه هستند. با هوش مصنوعی این کار از همیشه ساده تر شده است، اما بسیاری نمی دانند چگونه از آن استفاده کنند. AdCreative.ai پلتفرمی است که به شما امکان می دهد تبلیغات و خلاقیت های اجتماعی را با هوش مصنوعی ایجاد کنید.
شما می توانید از این ابزار برای ایجاد تبلیغات و کمپین های اجتماعی برای کسب و کارها و کسب درآمد از هوش مصنوعی استفاده کنید.
با AdCreative.ai می توانید:
- برای فیس بوک، اینستاگرام، گوگل، لینکدین، توییتر، پینترست و غیره تبلیغات ایجاد کنید.
- صدها خلاقیت را در چند ثانیه بدون هیچ گونه مهارت طراحی ایجاد کنید.
- نسخه ها و اندازه های مختلف تبلیغات خود را در چند ثانیه ارائه دهید.
- رتبه بندی تبلیغات خود را توسط هوش مصنوعی دریافت کنید.
اگر یاد بگیرید که چگونه از یک ابزار هوش مصنوعی مانند AdCreative.ai استفاده کنید، می توانید بسیار سریع تر از یک بازاریاب معمولی تبلیغات بسازید. این به شما امکان می دهد مشتریان بیشتری را جذب کرده و درآمد بیشتری کسب کنید. ایجاد تبلیغات برای سایر مشاغل یک راه بسیار سودآور برای کسب درآمد آنلاین است، زیرا همه باید محصولات یا خدمات خود را تبلیغ کنند.
۷- ساخت ویدیوهای YouTube
پس از گوگل، یوتیوب دومین وب سایت پربازدید در جهان است. پس چرا از آن برای کسب درآمد آنلاین استفاده نکنید؟ با ابزارهای هوش مصنوعی میتوانید بدون نمایش چهره خود و بدون تجهیزات گرانقیمت ویدیو بسازید.
یوتیوب بهترین بستر برای بازاریابی ویدیویی و افزایش مخاطبان است. شما می توانید از این پلتفرم برای کسب درآمد از تبلیغات یا فروش محصولات استفاده کنید. اگر محصول یا خدماتی برای تبلیغ ندارید، می توانید محصولات وابسته پردرآمد را به مخاطبان خود ارائه دهید.
برای کسب درآمد از هوش مصنوعی از طریق یوتیوب باید یک کانال YouTube ایجاد کرده و در آن ویدیو ارسال کنید.
برای مثال می توانید از ChatGPT برای ایجاد ایده های ویدیویی، اسکریپت های ویدیویی، سرفصل ها و توضیحات محصول استفاده کنید. همچنین با استفاده از AI با Synthesia ویدیو ایجاد کنید. Synthesia پلتفرمی است که از هوش مصنوعی برای ایجاد ویدیوهایی با ظاهر حرفه ای استفاده می کند. این ابزار با آواتارها، قالبها، کتابخانه رسانه رایگان، عناصر طراحی، موسیقی پسزمینه بدون حق امتیاز و موارد دیگر همراه است.
برای اطمینان از دریافت بازدیدهای بیشتر، می توانید از ابزاری مانند TubeBuddy برای بهینه سازی کانال و ویدیوهای خود استفاده کنید. TubeBuddy به شما امکان می دهد کلمات کلیدی مناسبی را برای ساختن ویدیوها پیدا کنید، بنابراین بتوانید در نتایج جستجو رتبه بالاتری کسب کنید. بیش از ۱۰ میلیون سازنده به آن اعتماد دارند و دارای برنامه های قیمتی بسیار مقرون به صرفه است.
یوتیوب یک راه عالی برای کسب درآمد آنلاین است، زیرا فرصت های زیادی برای کسب درآمد از مخاطبان خود دارید. هنگامی که ویدیوهای شما در نتایج جستجو رتبه بندی می شوند، ترافیک ارگانیک رایگان نیز دریافت می کنید که می تواند به مشتری تبدیل شود. یوتیوب یکی از بهترین راهها برای ایجاد درآمد غیرفعال است.
۸- ایده های ایجاد نام تجاری
ایجاد نام تجاری با ابزارهای AI یکی دیگر از روش های کسب درآمد از هوش مصنوعی است. شما می توانید از یک ابزار رایگان مانند ChatGPT استفاده کنید و ایده های نام تجاری را برای سایر مشاغل ایجاد نمایید. با سایت Namingforce می توانید ایده های خود را ارسال کنید و در صورت برنده شدن در مسابقات درآمد کسب کنید. این روش نیز یکی دیگر از راه های درامد دلاری با هوش مصنوعی است.
Namingforce وبسایتی است که در آن افراد میتوانند مسابقههایی را برای دریافت ایدههای نام برای کسبوکار خود ایجاد کنند. شما به عنوان یک نامگذار میتوانید نامهایی را ایجاد و ارسال کنید تا در مسابقه برنده شوید.
با استفاده از ChatpGPT میتوانید ایدههای نامی مرتبط با آن کسبوکار خاص ایجاد کنید. این به شما ایده هایی برای نام یک کسب و کار خاص می دهد که می توانید به Namingforce ارسال کنید. می توانید ورودی را تغییر دهید تا نام هایی با سبک ها و طول های مختلف ایجاد کنید.
این مقاله را حتما بخوانید: برنامه ریزی و هدف گذاری در سال 1402 با 10 گام کاملا عملی
۹- یک مشاور سئو شوید خدمات سئو
آیا می خواهید به سازندگان محتوا کمک کنید تا در نتایج جستجو رتبه بالاتری کسب کنند؟ با یادگیری بهینه سازی موتورهای جستجو (SEO) می توانید با کمک به وبلاگ ها در تحقیقات کلمات کلیدی و سئوی درون صفحه درآمد کسب کنید.
با وجود اینکه داشتن تجربه در هنگام تبدیل شدن به یک مشاور سئو مزیت دارد، می توانید بیشتر کارها را با هوش مصنوعی انجام دهید. با استفاده از SEO.ai شما تمام ابزارهای مورد نیاز برای انجام تحقیقات کلمات کلیدی، ایجاد محتوای بهینه شده برای سئو و انجام سئوی درون صفحه را در اختیار دارید. این به مشتریان شما کمک می کند تا رتبه بالاتری در گوگل کسب کنند.
اگر بتوانید به آنها کمک کنید پول بیشتری کسب کنند، مردم پول خوبی می پردازند. با بودن یک مشاور سئو می توانید به وبلاگ نویسان جدید کمک کنید تا وب سایت های خود را در گوگل رتبه بندی کنند و برای انجام این کار پول دریافت کنند.
۱۰- ساخت اسکریپت های ویدیویی برای تولیدکنندگان محتوا
سازندگان محتوا همیشه به دنبال ایده ها و فیلمنامه های ویدئویی هستند. اگر میخواهید به ناشران کمک کنید تا محتوای بهتری عرضه کنند، پس این راه کسب درآمد از هوش مصنوعی برای شما مناسب است.
با استفاده از ابزارهای هوش مصنوعی این فرآیند یکپارچه و راحت می شود. برای ایجاد اسکریپتهای ویدیویی میتوانید از ابزار رایگان ChatGPT یا نویسندگان هوش مصنوعی پیشرفتهتر مانند Jasper.ai استفاده کنید.
نوع اسکریپت های ویدئویی که می توانید ایجاد کنید شامل موارد زیر می باشد:
- برای افزایش فروش اسکریپت های ویدیویی ایجاد کنید.
- اسکریپت های ویدیویی برای ویدیوهای یوتیوب بسازید.
- اسکریپت های ویدئویی حرفه ای برای مشاغل بسازید.
- اسکریپت های ویدیویی آموزشی تولید کنید.
- اسکریپت های دوره دیجیتال بسازید.
- اسکریپت های وبینار تولید نمایید.
شما میتوانید هر آنچه را که میخواهید برای خدمات خود شارژ کنید، اما اگر به Fiverr بروید، اکثر سازندگان فیلمنامه از ۵ دلار شروع میکنند. برخی حتی از ۱۴۰ دلار یا بیشتر شروع می شوند. با استفاده از ابزارهای هوش مصنوعی میتوانید اسکریپتهای ویدیویی را سریعتر بنویسید و درآمد بیشتری به صورت آنلاین داشته باشید.
کسب درآمد از ChatGPT ابزار تولید محتوا
اگر به دنبال ابزارهای هوش مصنوعی برای کسب درآمد هستید، ChatGPT محصول شرکت OpenAI ارزش توجه را دارد. این ربات چت به دلیل موارد استفاده باورنکردنی و متنوعش، دنیای تکنولوژی و اینترنت را متحول کرده است.
این یک مدل زبانی بزرگ است که می تواند به همه سؤالات شما به شیوه ای دقیق پاسخ دهد. از تولید ایدهها و طرحهای کلی برای ایجاد محتوای باکیفیت گرفته تا ارائه پیشنهادات برای بهبود و تصحیح کارتان می توانید از این فناوری جدید استفاده کنید.

روش های کسب درآمد از چت جی پی تی
چگونه با استفاده از ChatGPT درآمد کسب کنیم؟
برای کسب درآمد از چت جی بی تی چند راه وجود دارد که در ادامه به چند مورد از آنها اشاره می کنیم.
ایجاد کسب و کار تولید محتوا به صورت آزاد
ChatGPT یکی از بهترین ابزارهای نوشتن با AI و کسب درآمد از هوش مصنوعی است. این ابزار برای کمک به تولیدکنندگان محتوا برای ایجاد محتوای وب سایت، صفحات اصلی سایت، پست های رسانه های اجتماعی، پست های وبلاگ و غیره است. علاوه بر این، chatGPT به شما کمک می کند تا با ایجاد ایمیل و پیشنهادات با مشتریان خود ارتباط برقرار کنید.
فروش برنامه های چت بات
می توانید از ChatGPT برای ایجاد برنامه های Chatbot و سپس مجوز یا فروش این برنامه ها به افراد یا مشاغل استفاده کنید. این برنامه ها به عنوان کمک مجازی، خدمات مشتری و غیره عمل می کنند.
ساخت و فروش ویدئو
با استفاده از قابلیت تبدیل متن به گفتار ChatGPT، میتوانید برای ویدیوهای خود صدا ایجاد کنید و میتوانید این ویدیوها را برای درآمدزایی بفروشید. علاوه بر این، میتوانید از ChatGPT برای بهروزرسانی توضیحات ویدیوی یوتیوب خود با تمرکز بر SEO استفاده کنید. همچنین می توانید خدمات خود را به عنوان متخصص بهینه سازی سئو ارائه دهید.
خود انتشار کتاب های الکترونیکی
میتوانید از ChatGPT برای نوشتن کتابهای الکترونیکی استفاده کنید و سپس این کتابها را بر اساس اشتراک یا دسترسی فروش به محتوای خود، بفروشید.
بازار کار هوش مصنوعی چگونه است؟
بازار کار هوش مصنوعی در حال حاضر در حال رشد و گسترش قابل توجهی است. با توجه به پیشرفت سریع تکنولوژی و نیازهای روزافزون برای حل مسائل پیچیده، فرصتهای شغلی در حوزه هوش مصنوعی به طور مداوم در حال افزایش است. برخی از جوامع شغلی و موقعیتهای شغلی مرتبط با هوش مصنوعی عبارتند از:
۱- مهندسان هوش مصنوعی: افرادی که در طراحی، توسعه و پیادهسازی الگوریتمها، مدلها و سیستمهای هوش مصنوعی مهارت دارند. این افراد می توانند به راحتی از طریق روش های بیان شده در بالا، کسب درآمد از هوش مصنوعی را تجربه کنند.
۲- دادهشناسان: افرادی که تخصص در تجزیه و تحلیل دادهها، استخراج اطلاعات و ارزیابی کیفیت دادهها را دارند.
۳- متخصصان یادگیری ماشین و تحلیل پیشبینی: افرادی که توانایی تحلیل دادهها، ساخت مدلهای پیشبینی و بهبود الگوریتمهای یادگیری ماشینی را دارند و می توانند کسب درآمد از هوش مصنوعی داشته باشند.
۴- متخصصان پردازش زبان: افرادی که در فهم و تفسیر زبان تخصص دارند و قادر به توسعه سیستمهایی هستند که قادر به تحلیل و پردازش متون و اطلاعات زبانی هستند.
۵-توسعهدهندگان نرمافزار: افرادی که توانایی توسعه و پیادهسازی نرمافزارهای هوشمند و برنامههای کاربردی را دارند.
۶- متخصصان امنیت هوش مصنوعی: افرادی که در امنیت و حفاظت از سیستمها و الگوریتمهای هوش مصنوعی تخصص دارند.
درآمد هوش مصنوعی در ایران
بررسی درآمد در حوزه هوش مصنوعی در ایران نشان میدهد که این حوزه در کشور در حال رشد است و با توجه به اهمیت و کاربرد گستردهای که دارد، پیشبینی میشود در آینده نیز رشد خوبی داشته باشد. هوش مصنوعی به عنوان یک فناوری جذاب و پرکاربرد قابلیت کسب درآمد را به روشهای مختلفی ارائه میدهد.
برای کسب درآمد از هوش مصنوعی، از طریق استفاده از روشهای مختلفی مانند یادگیری ماشینی و تحلیل دادهها میتوان در حوزههای مختلفی مانند فناوری اطلاعات، پزشکی، صنعت و خدمات فعالیت کرد.
در حال حاضر در ایران، افرادی که در حوزه هوش مصنوعی فعالیت میکنند، میتوانند در شغلهای مرتبط با تحلیل اطلاعات، مهندسی مدلها، برنامهنویسی، هوش تجاری و ماشین لرنینگ، فعالیت کنند. همچنین، با توجه به کاربرد گسترده هوش مصنوعی در صنایع مختلف، نیاز به متخصصان این حوزه در شرکتهای نرمافزاری، شرکتهای فناوری اطلاعات و سایر صنایع وجود دارد.
این مقاله را حتما بخوانید: برندگان جشنواره برترین پیج های اینستاگرام ایران مشخص شدند - آکادمی کلاته

چرا یادگیری هوش مصنوعی اهمیت دارد؟
اهمیت یادگیری هوش مصنوعی
یادگیری هوش مصنوعی اهمیت زیادی دارد زیرا:
قادر به حل مسائل پیچیده است: هوش مصنوعی قادر است الگوها و روابط پیچیده را در دادهها شناسایی کرده و مسائل پیچیده را حل کند که برای انسانها ممکن است دشوار یا زمانبر باشد.
بهبود تصمیمگیری: یادگیری هوش مصنوعی میتواند به ما در فرآیند تصمیمگیری کمک کند. با تجمیع و تحلیل حجم زیادی از دادهها، هوش مصنوعی میتواند الگوها و روابطی که در تصمیمگیری موثر هستند را شناسایی کرده و به ما راهنمایی کند.
افزایش بهرهوری: استفاده از هوش مصنوعی میتواند به بهبود عملکرد و بهرهوری در صنایع و سازمانها کمک کند. با استفاده از الگوریتمها و مدلهای هوش مصنوعی، فرآیندها به طور خودکار و هوشمندانهتر انجام میشوند که منجر به صرفهجویی در زمان، هزینه و منابع میشود.
توسعه فناوریهای پیشرفته: یادگیری AI و کسب درآمد از هوش مصنوعی نقش مهمی در توسعه فناوریهای پیشرفته از قبیل خودرانها، رباتها، سیستمهای پردازش زبان طبیعی و بسیاری از برنامههای هوشمند دیگر دارد.
پتانسیل ایجاد تغییرات مثبت: این حوزه علمی و فناوری قدرت بزرگی برای ایجاد تغییرات مثبت در جوامع و جهان دارد.
چند توصیه مهم برای شروع کسب درآمد از هوش مصنوعی
برای شروع کسب درآمد از هوش مصنوعی، بهتر است به توصیههای زیر توجه کنید:
۱- آموزش و یادگیری: مهارتهای هوش مصنوعی را به طور کامل فرا بگیرید. مطالعه در حوزههای مرتبط مانند یادگیری ماشین، شبکههای عصبی و الگوریتمهای هوشمند اهمیت بسیاری دارد.
۲- انتخاب حوزه مورد علاقه: پیشنهاد میشود در حوزهای که به آن علاقهمند هستید و تجربه دارید، کار کنید. این به شما کمک میکند تا با اشکال و چالشهای مرتبط با آن حوزه آشنا شوید و بهترین استراتژیها را برای کسب درآمد از هوش مصنوعی تعیین کنید.
۳- ایجاد پروژههای عملی: سعی کنید پروژههای عملی و قابل اجرا را طراحی و پیادهسازی کنید. این پروژهها میتوانند شامل توسعه نرمافزار، تحلیل دادهها یا ساخت مدلهای پیشبینی باشند. این کارها به شما در کسب تجربه و نمونه کار قابل نمایش به مشتریان کمک میکند.
۴- ایجاد شبکههای ارتباطی: ارتباط با افراد و شرکتهای فعال در حوزه هوش مصنوعی بسیار ارزشمند است. شرکت در جلسات، کنفرانسها و جامعههای مرتبط، امکان معرفی به متخصصان و جذب پروژهها و همکاریهای جدید را فراهم میکند.
۵- ارائه خدمات و محصولات: شروع به ارائه خدمات مشاوره، طراحی نرمافزارهای هوشمند یا توسعه مدلهای پیشبینی می تواند به شما در کسب درآمد از هوش مصنوعی کمک کند.
تجربیات خود در زمینه کسب درآمد از هوش مصنوعی را با ما در میان بگذارید
در این مطلب به نقد و بررسی تخصصی کسب درآمد از هوش مصنوعی پرداختیم. فناوری هوش مصنوعی طیف گسترده ای از فرصت ها را برای افرادی که به دنبال کسب درآمد هستند باز کرده است. با رشد مداوم صنعت AI، ابزارها و منابع بیشتری برای کمک به افراد برای سرمایه گذاری در این حوزه ایجاد شده است. چه مهارت های برنامه نویسی داشته باشید یا نه، راه های زیادی برای کار با هوش مصنوعی و کسب درآمد با استفاده از این ابزارها وجود دارد.
یکی از هیجان انگیزترین چیزها در مورد کسب درآمد با هوش مصنوعی این است که امکانات در این زمینه تقریباً بی پایان است. همانطور که تکنولوژی به تکامل خود ادامه میدهد و کسبوکارها و صنایع بیشتری از هوش مصنوعی استفاده میکنند، فرصتهای بیشتری برای افراد وجود خواهد داشت تا از این روند استفاده کنند.
با این حال، مهم است در نظر داشته باشید که هوش مصنوعی یک زمینه به سرعت در حال توسعه است و باید با آخرین پیشرفت ها و روندها در این زمینه بروز باشید. به طور کلی، کسب درآمد با ابزارهای هوش مصنوعی راهی عالی برای استفاده از این صنعت رو به رشد و توسعه مهارت های جدید است.
با کمی خلاقیت و تمایل به یادگیری، هر کسی می تواند با استفاده از فناوری هوش مصنوعی درآمد بیشتری کسب کند. اگر می خواهید برای تولید محتوا از هوش مصنوعی استفاده کنید، پیشنهاد می کنیم مقاله ما در مورد دوره تولید محتوا با هوش مصنوعی را مطالعه کنید. لازم به ذکر است که اگر شما نیز با انواع هوش مصنوعی آشنا هستید و تا به حال تجربه کسب درآمد از هوش مصنوعی را داشته اید، آن را با ما در میان بگذارید.
سوالات متداول
آیا می توان با هوش مصنوعی کسب درآمد کرد؟
بله! می توانید از هوش مصنوعی برای ساخت وب سایت استفاده کنید. سپس می توانید آن سایت ها را بفروشید یا از آنها برای ایجاد درآمد از طریق بازاریابی وابسته، گوگل ادوردز یا اشتراک استفاده کنید.
استارتآپهای هوش مصنوعی چگونه کسب درآمد میکنند؟
شرکتهای هوش مصنوعی میتوانند با جمعآوری، تجزیه و تحلیل و فروش اطلاعات با ارزش به مشتریان درآمد کسب کنند، بهویژه اگر شرکت هوش مصنوعی در برنامههای هوش مصنوعی مبتنی بر دادهها متخصص باشد.
آیا هوش مصنوعی یک مهارت با درآمد بالا است؟
هوش مصنوعی و یادگیری ماشینی جزو پردرآمدترین مهارتها در سال ۲۰۲۳ هستند. طبق گزارش مجمع جهانی اقتصاد، هوش مصنوعی احتمالاً تا سال ۲۰۲۵، حدود ۹۷ میلیون شغل جدید ایجاد میکند. همچنین تقاضای شغلی را تا ۸۵ میلیون در صنایع خاص کاهش میدهد.
جایگاه هوش مصنوعی ۱۰ سال دیگر کجا خواهد بود؟
بر اساس تحقیقات جدید، هوش مصنوعی ممکن است بتواند حدود ۳۹ درصد از کارهای خانگی را ظرف ۱۰ سال آینده خودکار کند.
تجارت در بازارهای مالی براساس هوش مصنوعی چگونه کار می کند؟
سیگنالهای معاملاتی توسط سیستمهای هوش مصنوعی بر اساس تجزیه و تحلیل پیشرفته شاخصهای متعدد، مانند عملکرد قیمت، ارزشگذاری ارز و حتی تجزیه و تحلیل دادههای مربوط به دارایی خاص در اخبار و رسانههای اجتماعی تولید میشوند. تحلیل تکنیکال پویایی قیمت سهام نیز در مجموعه داده گنجانده شده است.
آیا یادگیری هوش مصنوعی سخت است؟
یادگیری هوش مصنوعی برای بسیاری از افراد، بهویژه کسانی که پیشزمینه علوم کامپیوتر یا برنامهنویسی ندارند، دشوار است. با این حال، ممکن است ارزش تلاش لازم برای یادگیری آن را داشته باشد. تقاضا برای متخصصان هوش مصنوعی احتمالاً افزایش می یابدُ زیرا شرکت های بیشتری شروع به طراحی محصولاتی می کنند که از هوش مصنوعی استفاده می کنند.
https://irfoundr.com/making-money-from-ai/






 . برای مثال، کلاس مفهومی میتواند مجموعه فرمولهای
. برای مثال، کلاس مفهومی میتواند مجموعه فرمولهای  . در مدل PAC (و مدل آگنوستیک مربوطه)، این به طور قابل توجهی تعداد نمونههای مورد نیاز را کاهش نمیدهد: برای هر کلاس مفهومی، پیچیدگی نمونه کلاسیک و کوانتومی تا فاکتورهای ثابت یکسان است.
. در مدل PAC (و مدل آگنوستیک مربوطه)، این به طور قابل توجهی تعداد نمونههای مورد نیاز را کاهش نمیدهد: برای هر کلاس مفهومی، پیچیدگی نمونه کلاسیک و کوانتومی تا فاکتورهای ثابت یکسان است.  و|1〉
و|1〉 در نماد دیراک
در نماد دیراک  ، به عنوان احتمال تشخیص فوتودیاب فوتونی که به آن می رسد تعریف می شود.
، به عنوان احتمال تشخیص فوتودیاب فوتونی که به آن می رسد تعریف می شود.  برای یک تخلف بدون حفره مورد نیاز است.
برای یک تخلف بدون حفره مورد نیاز است.  ،
،  .
. 





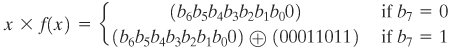
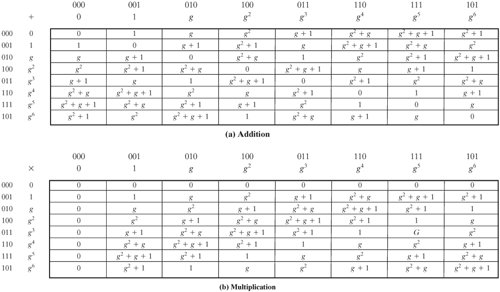
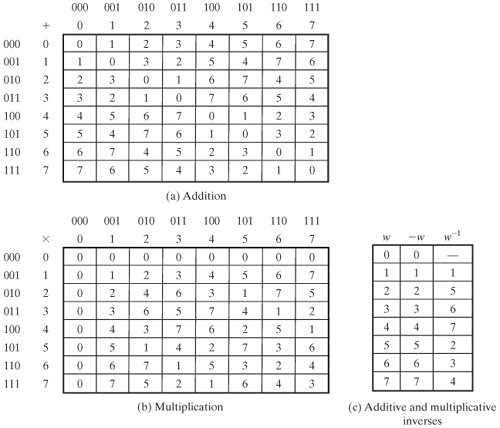
 (00011011) = (01000111)
(00011011) = (01000111)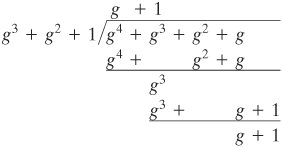

 4 آرایه DRAM
4 آرایه DRAM.png)